


编辑:前沿在线 编辑部
过去这三个月,圈子里那叫一个冰火两极分化。
走访多家企业信息化负责人后能明显感知,不少落地未满一年的AI数据分析系统正遭遇“降温”,部分团队暂停了新上线的AI系统,重新回归Excel人工核算的传统工作模式。

问起原因,某零售集团的数字化总监一句话道出了普遍痛点:“这玩意儿吐出来的经营数据波动很大,稳定性不足,今日、明日的核算结果差异明显。
没人敢拿公司几个亿的业务盘子,去赌AI输出结果的稳定性。”
2025 年是 AI Agent的资本狂欢年,厂商们拿着几个炫酷的演示 Demo 就能在资本市场上长袖善舞。
但进入 2026 年,行业正式撞上了残酷的落地验收期。
MIT 2025年《The GenAI Divide》权威调研的数据直接撕开了这层遮羞布:95%企业AI试点项目无法创造可量化的业务价值,多数项目长期停滞在试点阶段,难以规模化应用。

但诡异的是,市场的采购大盘依然烈火烹油。这种旺盛的需求与稀烂的落地效果背后,是供给端厂商基因的彻底分化。
冷酷的现实最终指向同一个结论:企业级 Agent 落地受阻,核心问题从来不是大模型本身的参数不够、智商不足,而是缺失全链路的工程化约束。

为什么那些在 C 端聊天扯淡、写诗作画无所不能的通用大模型,一进 B 端企业的生产环境就普遍翻车?
说白了,现在市面上大部分 B 端 Agent,就是“通用大模型 API 套个好看的壳”。

不少侧重产品演示与市场包装的厂商,习惯了 C 端哄用户开心、轻量化交互的产品哲学,试图跳过企业数据治理、推理管控、安全合规这三大底层苦活累活。
这种脱离企业底层业务与数据体系的落地方式,很难适配复杂B端场景。缺少行业数字化底座的大模型厂商,在对接企业核心业务时,普遍会遭遇三大落地难题。
首先是数据口径的混乱,导致跨部门数据“鸡同鸭讲”。
企业搞了数十年数字化,内部系统早已形成独立的业务体系与数据规则。
同样是“收入”两个字,销售、财务、运营各有统计标准——销售指合同额,财务看实收保费或实际回款,运营认定是发货额。
通用大模型无法识别企业个性化的业务口径,只能做字面上的语义连线题。

某股份制银行就吃过这个亏,测试某头部大模型的智能分析产品时,系统直接把所有的“新增开户记录”字面等同于了“新客户”,最终输出报表严重失真。
一旦数据对不上,研发只能在前端反复调试提示词(Prompt),按下葫芦起了瓢,无法从根源解决口径混乱的问题。
其次是黑盒决策不可溯源,导致核心决策权难以开放。
通用大模型基于概率生成的特性,注定了它的推理是不可见的“黑盒”。
在 C 端场景,AI 偶尔产生幻觉胡说八道,用户顶多一笑置之;但在冰冷的商业现场,一次测算失误,代价往往是几百万甚至上千万的真金白银。
某快消企业在大促期间让 Agent 算 ROI,系统由于缺乏底层业务与数据底座,错误调用了三年前的历史数据集,导致促销策略方向性失误,几百万营销成本直接损耗。
事后复盘时,因为底层没有完整的链路追踪能力,企业无法精准定位AI调用、计算、推理的问题节点,责任划分无据可依。

高管们在引入企业级AI时趋于保守,核心原因就是无法可视化AI完整的计算与推理链路,多数大模型产品无法提供标准化步骤快照,难以匹配企业严苛的审计和合规要求。
最后是底层安全架构的缺失,难以满足强监管行业的落地门槛。
在强监管行业,数据域隔离、精细化权限管控是不可触碰的高压红线。
然而,多数大模型厂商的安全架构原生适配开放式C端场景,并不适配企业严苛的风控体系。
今年一季度被通报的几起企业级 Agent 平台严重安全漏洞,底层根源都是系统缺乏内核级隔离,面对提示词注入(Prompt Injection)攻击时防护薄弱。
某央企信息安全负责人曾直言,多款市面产品连基础的精细化权限管控都无法实现。
部分通用 Agent 因代码执行权限过高,在数据清洗过程中误删企业服务器核心业务文件,造成业务中断数十小时。
这类核心安全隐患,绝非简单在前端添加“本地部署开关”就能彻底解决。

面对这三类落地难题,2026 年整个政企客户市场的采购逻辑发生了根本性的逆转:大家不再关心大模型的榜单跑分和参数规模,转而重点考察落地案例、口径治理能力以及安全合规水平。

结合Gartner公开预测内容,到 2027 年,70% 的企业级 AI 应用将落地工程化约束架构。
业界也逐渐达成了一个共识:大模型就像一头无所不能的“野马”,而企业级应用买的不是赛马场上的狂奔,买的是拉磨干活的确定性。
所以,行业真正缺的不是模型,而是给野马配套的硬核马具——工程化约束(Harness)架构。
所谓的 Harness 架构,不是前端简单的调调提示词,而是包含了指标管控、流程编排、知识库、运行沙箱等核心模块,可实现全链路工程化约束与安全治理的完整体系。

在搭建这套工程化马具时,市场上演了两条截然相反的路线,这也成了决定落地生死的胜负手。
大模型厂商走的是“自上而下的适配”路线,拿着现成的野马,试图在外面焊上一层铁笼子,但因为触及不到底层数据和长年累月的业务规则,笼子往往是漏风的。
与之相对的,是自下而上的融合路线,深耕企业数字化赛道的老牌BI厂商便是该路线的典型代表。
这类厂商常年服务政企数字化建设,天然沉淀了企业成熟的指标体系、业务规则和安全权限底座,叠加大模型能力后,可直接在企业原生数据底座上搭建合规、可控的AI工程化体系。

在这个行业大趋势下,老牌 BI 厂商里玩得最绝、动作最快的,是以思迈特最近发布的白泽 V5 为代表的纯正 BI 原生派。
作为一个典型的“解题样本”,白泽 V5几乎成了这条“融合路线”的极简对照组。多数同行仍选择在传统架构上叠加AI能力,侧重可视化与轻量化分析。
而白泽V5 跳出了“BI + 外挂大模型”的常规路径,直接重构底层架构,打造出 “统一指标模型 + 多智能体协同” 的双轮底座:
前者筑牢企业可信数据底座,统一全业务口径、根治数据混乱问题;后者可拆解复杂分析任务,实现多角色智能分工协作、全程链路追溯与动态人工干预。
我们可以通过它在实际业务场景里跟数据的肉搏过程,来看看老牌 BI 厂商到底是怎么在 B 端把大模型驯服的。

要验证一个 B 端 Agent 究竟是 PPT 里的故事,还是真枪实弹的生产力工具,不能听它宣称的智能上限,得看它敢不敢把自己扔进政企最核心的业务泥潭里。
白泽 V5 之所以能被挑剔的国有大行和能源巨头放行,靠的就是在底层工程上,用一种近乎“死磕”的克制,解掉了行业最痛的三道题。
第一道防线,是用“指标钢筋”稳住崩溃的用数现场,重塑行业价值。
在企业的数字化管理中,最荒唐也最常见的场景,莫过于周一的经营例会上,销售、财务、运营三个部门拿出的数据完全对不上,跨部门开会变成了互相扯皮的大战。
大模型在没有约束的情况下进入这种现场基本就是灾难——它会用最流畅的套话,编造最离谱的错误数字。

在某头部保险集团的数智化落地现场,这种复杂用数困局正是白泽 V5 的战场。整个集团盘踞着 50 多个复杂的业务维度和 400 多项核心财务指标。
如果按照传统的套壳 AI 做法,业务人员问一句“上月保费营收波动主因”,大模型大概率会分不清口径而在底层胡乱连线。
白泽 V5 的解法是在底层焊死一套“标准化指标引擎”。

当业务输入查询时,系统会保持极致严谨的运行逻辑:优先在已经对齐、建档的指标资产库里做硬匹配。
如果是定义好的标准指标,直接调用确定性的计算引擎吐出结果;一旦遇到库里没有的、定义模糊的“野生口径”,系统会严格恪守业务严谨性,弹出提示框要求业务人员补充语境,绝不允许大模型凭借泛化能力凭空编造数据与结论。
这种自下而上的底层重构,与目前市场上传统 BI 厂商普遍采用的“旧架构外挂大模型接口”(即底层指标依然靠人工,前端只管用 AI 对话的“事后治理”模式)有着代差级的区别。
它把指标管理直接前置到了数据接入的一刻。
最终,该保险集团不仅精准、自动地拆解出了营收波动的各项要素贡献占比,往常跨部门吵得不可开交的荒唐场景也基本成了历史。
更重要的是,它能直接兼容企业过去在 SmartBI 上沉淀的所有存量历史数据集和报表,让企业过去的数字化投资,引入 AI 时不需要经历痛苦的“推倒重来”。
第二道防线,是用“白盒协同”击碎管理的黑盒恐惧,让实践链路可复现。
任何一个理智的管理者,都不可能把上百万的营销预算或者上亿的电力催收决策,交到一个说不清推理过程的“黑盒”AI 手里。
B 端要的不是一个全能的聊天秘书,而是一个分工明确、步步留痕的专业团队。

这种生产力的重塑,在某省级电网的电费归因与催收现场,被复现出了一条高度具象的流水线。
面对庞大的用户用电数据集,白泽 V5 在底层摒弃了“一个万能模型包办一切”的作坊模式,而是把数据分析任务拆成了查询智能体、归因智能体、报告智能体等多个专项多智能体,通过 ReAct 机制让他们自主协作。
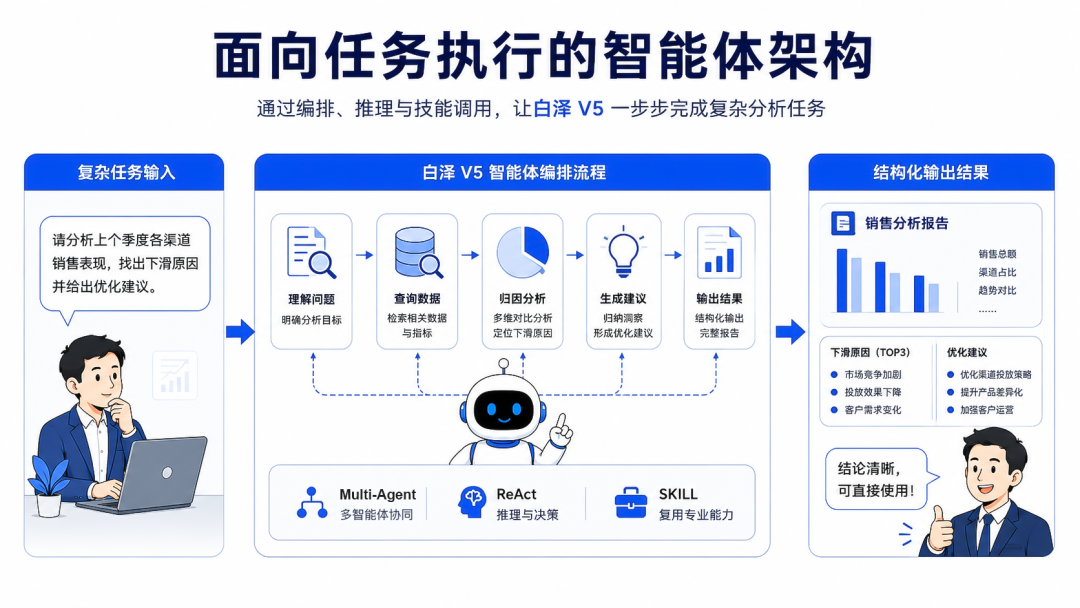
当系统运转时,后台会根据业务流转自动调度SQL、Spark、MDX、Python沙箱这四种算力引擎。
查询智能体先调取海量异构数据,归因智能体随即接管,自主构建高风险用户画像并分析欠费主因,最后由报告智能体自动生成催收方案并跟踪效果。

而它最让企业审计和财务总监放心的行业实践在于“全链路白盒推理”。
AI 吐出的不再只是一个孤零零的催收名单,在对话框里,它调用的每一张原始数据表、使用的每一个计算公式、每一步在语义层做出的推理逻辑,全部像快照一样白纸黑字地展示给用户看。
如果高管发现最后的归因结果有点不对劲,可以随时在计算链路的中间步骤进行人工干预和修正。
这种透明性,直接击碎了传统通用 Agent 无法溯源的行业顽疾,让 AI 真正敢被用在核心决策上。
第三道防线,是用内核级沙箱通过金融级强监管,筑牢安全底线。
在金融和政务等强监管行业,数据安全从来不是加分项,而是“一票否决项”。
大模型代码执行(Code Interpreter)功能在带来强大分析能力的同时,也带来了巨大的安全黑洞。一旦遭遇高阶的提示词注入攻击,黑客能直接利用 AI “越狱”拿到服务器的核心权限。

在实际落地中,目前多数厂商的安全方案依然停留在粗粒度表级权限管控(即这张表你能看、他不能看),或是仅部署进程级基础沙箱,防护强度有限。
白泽 V5 能够入选多家具备极高合规要求的国有大行采购选型清单,靠的是把安全架构直接嵌进了底层的骨子里。

在权限上,它的数据权限网关可以精确到每个单元格的访问权限。
而在代码执行防护上,它在底层采用的是独立的微虚拟机(Micro-VM)沙箱。
这意味着,即使 AI 哪天在推理时由于遭遇恶意攻击、或者业务人员自己手抖写错了一句分析命令导致系统误操作,它也只能在独立的隔离虚拟机容器里瞎折腾,根本碰不到企业生产环境的生命线。
这种内核级的安全防御,成功帮企业在享受 AI 效率红利的同时,把合规红线守得滴水不漏。

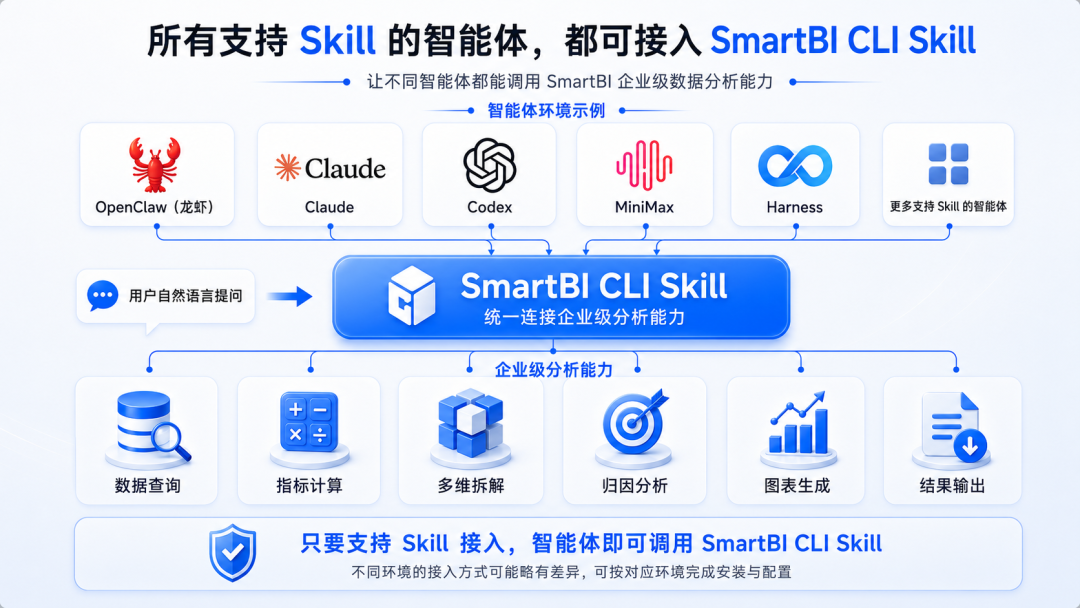
通过SmartBI CLI Skill,白泽V5还可接入OpenClaw(龙虾)、Claude等多款主流智能体生态,共享专业数据分析能力。
不过作为长年观察行业的第三方,我们也必须清醒地看到:白泽 V5 也绝非适合所有企业的灵丹妙药。
它天然更匹配数字化基础扎实、具备成熟 IT 资产体系的政企单位。对于内部数据、指标体系尚未成型的小微企业,优先夯实数据治理根基,再结合业务场景灵活启用对应功能,是更加务实的落地选择。

任何一项颠覆性技术的演进,都会经历相似的宿命。
企业 AI 的上半场,是一场属于通用模型、概念 Demo 和资本炒作的狂欢。
那时候市场把所有的镁光灯都打在了大模型的智能上限上,看它又卷了多少千亿参数、刷了什么榜单,却忽视了企业生产场景最核心的需求——可靠、可控、下限足够低。
依托MIT 2025年《The GenAI Divide》权威调研结论,95%企业AI项目无法落地产生实效的行业现状,让2026年的行业彻底撞破泡沫、加速回归理智。

未来的竞争,将不再是大模型参数的斗地主,而是工程化落地能力的贴身肉搏战。
在这场洗牌中,行业正在呈现两大趋势:
第一,指标治理与工程化约束(Harness)将成为事实上的行业准入标准。
仅靠套壳大模型、表层优化提示词的轻量化产品,市场适配空间将持续收缩。
大模型厂商在这场博弈中将逐渐演变为“基础设施提供商”,类似于发电厂,为具备行业 Know-how 的 BI 厂商或垂直领域深耕者提供底层的算力与模型支撑。
第二,存量资产复用能力将成为厂商的核心护城河。
面对复杂的宏观环境,企业会空前重视保护自己过去的数字化资产投资。任何要求企业把过去的报表和系统全部砸掉、推倒重来的方案,都很难获得客户认可。
这也是为什么长年深耕数字化落地、具备存量资产复用能力和客户沉淀的老牌 BI 厂商,能在本轮 Agent BI 大潮中掌握主动权。

与此同时,C端和B端智能体也将走向完全不同的发展路径:
C端产品向轻量化、全能化、泛娱乐化方向发展,容错空间较大;
B端产品则深耕垂直行业,以可信可控为第一准则。脱离数据治理与工程化约束,通用型 Agent 想要直接落地企业核心业务,并不具备可持续性。
企业级 AI 的上半场,拼的是大模型的“技术上限”;而决定生死存亡的下半场,拼的则是工程落地的“可靠下限”。
以白泽 V5 为代表的 BI 原生工程化智能体,用一笔笔扎实的政企落地订单,证明了一个最朴素的产业真理:企业级 AI 的核心价值,从来不是追求无所不能的绚丽,而是在规则的围栏内,将确定性做到极致。

那些真正愿意沉下心打磨工程化防线、解决企业信任赤字的厂商,终将在大浪淘沙后,成为留在桌上的真正赢家。
END –
